HED search details¶
HEDtools provides three distinct mechanisms for searching HED-annotated data. This page covers their design and query languages (implementations) and measured performance characteristics (performance).
HED search implementations¶
The three implementations share a common goal — “does this HED string match this query?” — but differ substantially in their inputs, capabilities, schema requirements, and performance characteristics. Choosing the right implementation depends on whether you need schema-aware ancestor matching, full group-structural queries, or raw throughput on unannotated strings.
Overview of the three implementations¶
basic_search — regex-based flat matching¶
Located in hed.models.basic_search, the find_matching() function operates directly on a pd.Series of raw HED strings using compiled regular expressions. It requires no schema and no parsing step, making it the fastest option for bulk row filtering.
Key characteristics:
Input is a
pd.Seriesof raw strings; output is apd.Series[bool]mask.The query is compiled once into a regex and applied with
Series.str.contains.Matches are purely literal —
Eventdoes not matchSensory-event.@Ain a basic-search query means A must be present anywhere in the string (note: this is the opposite of what@Ameans inQueryHandler/StringQueryHandler).~Ameans A must not appear anywhere (global negation).(A, B)syntax checks that A and B appear at the same nesting level.Wildcard
A*expands to the regexA.*?, which can span/and match mid-token substrings.
Use basic_search when you are working with a large collection of raw strings as a pd.Series, don’t need ancestor matching, and want maximum throughput. See hed.models.basic_search.find_matching().
QueryHandler — schema-backed object search¶
Located in hed.models.query_handler, QueryHandler is the full-featured search engine. It compiles a query string into an expression tree once, then evaluates that tree against HedString objects that have already been parsed against a loaded HedSchema.
Key characteristics:
Input is a
HedStringobject; a fullHedSchemais required.Output is a
list[SearchResult]containingHedTag/HedGroupobject references, useful for tag-level introspection (not just row filtering).Supports the complete query language:
&&,||,~,@,{},[],{:},?,??,???.@Ameans A must not appear anywhere in the string.Ancestor matching is exact — the schema normalises both query and string tags to short form, so
EventmatchesSensory-eventbecause the schema knowsSensory-eventdescends fromEvent.Per-string cost includes a full HedString parse and schema tag resolution.
Use QueryHandler when you need schema-aware ancestor matching, or when you want object references (e.g., to retrieve the matched group for further processing). See hed.models.query_handler.QueryHandler.
StringQueryHandler — tree-based schema-optional search¶
Warning
This facility is experimental. The API of hed.models.string_search and
hed.models.schema_lookup may change in future releases without notice.
These modules are not part of the stable public interface exported from
the top-level hed package. Import directly from the sub-modules.
Located in hed.models.string_search, StringQueryHandler is a middle-ground implementation that inherits from QueryHandler and reuses the full expression-tree compiler, but operates on raw strings rather than pre-parsed HedString objects.
It parses each raw HED string into a lightweight StringNode tree that duck-types the HedGroup/HedTag interfaces expected by the existing expression evaluators — so all QueryHandler query syntax works unchanged.
Key characteristics:
Input is a raw string (or a plain
list[str]viastring_search()).Schema is optional: pass a
schema_lookupdict (seehed.models.schema_lookup) to enable ancestor matching for short-form strings (e.g.EventmatchingSensory-event); omit it for purely literal matching.Output is a list (truthy/falsy) — row-filtering only, no object references.
Supports the same full query syntax as
QueryHandler(&&,||,~,@,{}, etc.).@Acarries the same semantics asQueryHandler— A must not be present.Long-form strings (
Event/Sensory-event) support ancestor matching via slash-splitting even without a lookup. Short-form strings (Sensory-event) require aschema_lookupfor ancestor matching; without one, matching is purely literal.Parse cost is a lightweight recursive split — much cheaper than a full HedString + schema parse.
Use StringQueryHandler when you have raw strings (not HedString objects), need the full QueryHandler query syntax, and either don’t have a schema available or want faster processing at the cost of losing full schema-aware ancestor matching. See hed.models.string_search.StringQueryHandler.
Generating a schema lookup¶
Note
hed.models.schema_lookup is part of the experimental string-search facility.
Its interface may change in future releases.
If you want StringQueryHandler to resolve ancestors for short-form strings (e.g. query Event matching Sensory-event) without a full schema parse per row, you can pre-generate a lookup dictionary from a HedSchema:
from hed import load_schema_version
from hed.models.schema_lookup import generate_schema_lookup, save_schema_lookup, load_schema_lookup
schema = load_schema_version("8.4.0")
lookup = generate_schema_lookup(schema) # {short_name_casefold: tag_terms_tuple}
# Persist for reuse
save_schema_lookup(lookup, "hed840_lookup.json")
lookup = load_schema_lookup("hed840_lookup.json")
Comparison tables¶
Core characteristics¶
Property |
|
|
|
|---|---|---|---|
Input |
|
|
Raw string or |
Schema required |
No |
Yes — full |
No; optional |
Output |
|
|
|
Result usable for |
Row filtering |
Row filtering + tag/group introspection |
Row filtering only |
Batch API |
|
Manual loop |
|
Parse cost |
Regex compilation once |
Full |
Lightweight tree parse per string |
Unrecognised tags |
Matched literally |
Silent match failure ( |
Matched literally |
Query syntax¶
Feature |
|
|
|---|---|---|
AND |
Space or comma between terms (context-dependent) |
|
OR |
Not supported |
|
Absent from string ( |
⚠️ |
|
Must-not-appear ( |
|
|
Prefix wildcard |
|
|
Full regex per term |
Yes ( |
No |
Quoted exact match |
No |
|
Implicit default |
If no |
No implicit conversion — must be explicit |
Group / structural operators¶
Feature |
|
|
|
|---|---|---|---|
Same nesting level |
|
N/A — use |
N/A — use |
Same parenthesised group |
No |
|
Same as |
Exact group |
No |
|
Same |
Optional exact group |
No |
|
Same |
Descendant group |
No |
|
Same |
Any child |
No |
|
Same |
Any tag child |
No |
|
Same |
Any group child |
No |
|
Same |
Nested query operators |
No |
Yes — full recursive composition |
Same |
Ancestor / cross-form search¶
Scenario |
|
|
|
|---|---|---|---|
Query |
❌ literal only |
✅ |
✅ with |
Query |
❌ |
✅ schema normalises |
✅ slash-split produces |
Query |
❌ |
✅ schema normalises both to short form |
❌ no schema to normalise |
Schema-free ancestor search |
|
N/A — schema always required |
✅ works natively for long-form strings |
Tag |
❌ literal prefix mismatch |
✅ |
✅ |
Critical semantic traps¶
These differences are silent — no error, just wrong answers if you mix up query strings across implementations:
Operator |
|
|
|---|---|---|
|
A must appear anywhere in the string |
A must not appear anywhere in the string |
|
A must not appear anywhere (global) |
A must not appear in any group that also matches the rest of the expression (local) |
|
Regex |
Strict prefix on the tag’s short form — anchored to start |
No-operator |
Both present anywhere (implicit |
Parse error — |
HED search performance¶
Benchmarks were run using HED 8.4.0 with timeit on both synthetic strings and real BIDS event data. All times are medians in milliseconds. Relative ratios between engines are more meaningful than absolute values, which depend on hardware.
Benchmark query suite¶
All 18 operations below are used across the benchmarks. The single-string and list benchmarks use the 12-query core set (rows marked ✓); the per-operation sweep uses all 18 on a fixed structured string; nesting-depth sweeps use the 5-query subset marked †.
Category |
Label |
Object search / String search query |
Basic search query |
Core |
Depth |
|---|---|---|---|---|---|
Simple |
|
|
|
✓ |
† |
Simple |
|
|
— unsupported |
✓ |
|
Simple |
|
|
|
✓ |
|
Boolean |
|
|
|
✓ |
† |
Boolean |
|
|
|
✓ |
|
Boolean |
|
|
|
||
Boolean |
|
|
— unsupported |
✓ |
|
Boolean |
|
|
|
✓ |
† |
Boolean |
|
|
— unsupported |
||
Boolean |
|
|
— unsupported |
||
Group structural |
|
|
|
✓ |
† |
Group structural |
|
|
— unsupported |
✓ |
† |
Group structural |
|
|
— unsupported |
✓ |
|
Group structural |
|
|
— unsupported |
✓ |
|
Group structural |
|
|
— unsupported |
||
Group structural |
|
|
— unsupported |
||
Complex |
|
|
— unsupported |
||
Complex |
|
|
— unsupported |
✓ |
Key findings¶
Batch throughput: basic search is ~16× faster than an object search row-by-row loop at 5 000 rows because it leverages vectorized pandas
str.contains; string search (plain list) is ~1.5× faster than object search.Single-string speed: string search (no lookup) is ~39% faster than object search per string because it avoids schema-based
HedStringconstruction.Schema-lookup overhead: enabling
schema_lookupin string search has negligible overhead for most queries; cost appears only when ancestor matching is actually invoked.Nesting depth: at depth 20, object search is ~8× slower than on a flat string; string search shows similar scaling (~8×).
Operation coverage: basic search supports 7 of 18 tested operation types. The remaining 11 (OR, exact groups, logical groups,
?/??/???wildcards, quoted terms) require object search or string search.
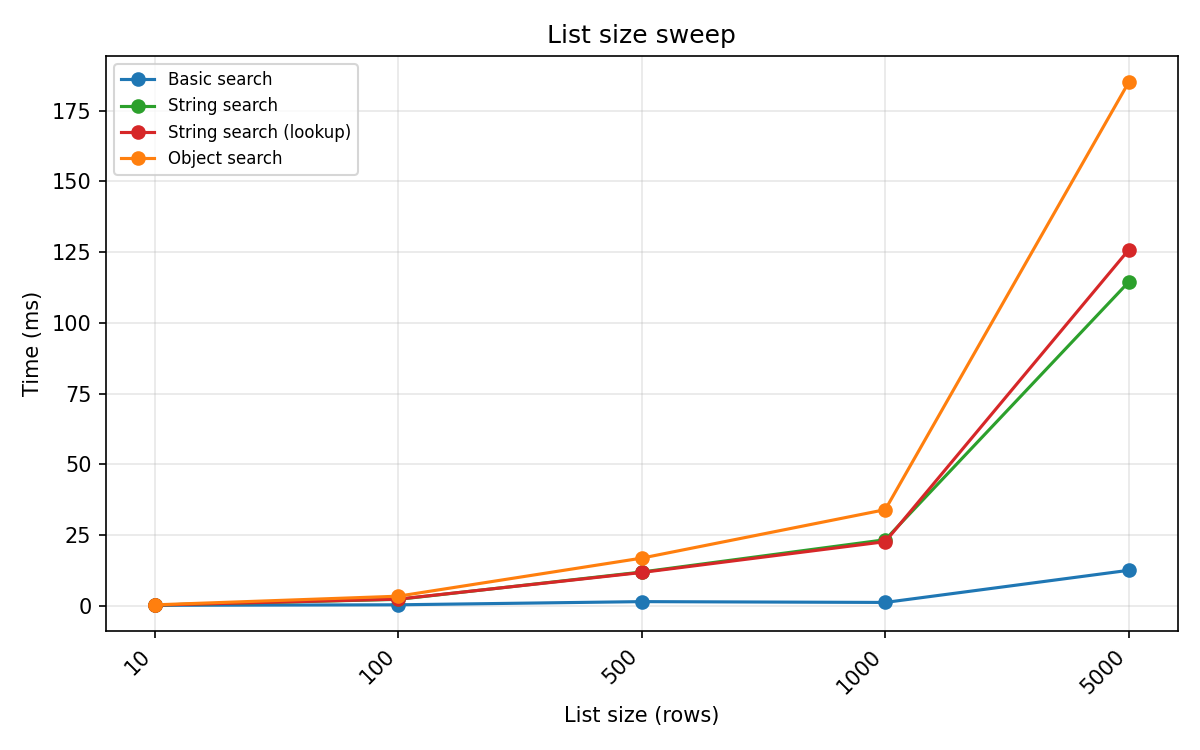
Row-by-row search scaling¶
Search over a list of HED strings of increasing length. Basic search uses vectorized pandas regex on a pd.Series. String search calls .search() per element on a plain list; object search constructs a HedString per row then searches. Query: bare_term (Event / @Event).
Rows |
Object search (ms) |
Basic search (ms) |
String search (ms) |
|---|---|---|---|
10 |
0.29 |
0.29 |
0.26 |
100 |
3.62 |
0.57 |
3.33 |
500 |
15.6 |
1.42 |
12.2 |
1 000 |
31.7 |
1.22 |
22.8 |
5 000 |
180 |
11.3 |
118 |
Basic search scales sub-linearly because vectorized regex amortises overhead across rows. String search and object search scale linearly (fixed per-row cost). Basic search is ~16× faster than object search at 5 000 rows; string search is roughly 1.5× faster than object search.
Single-string timing¶
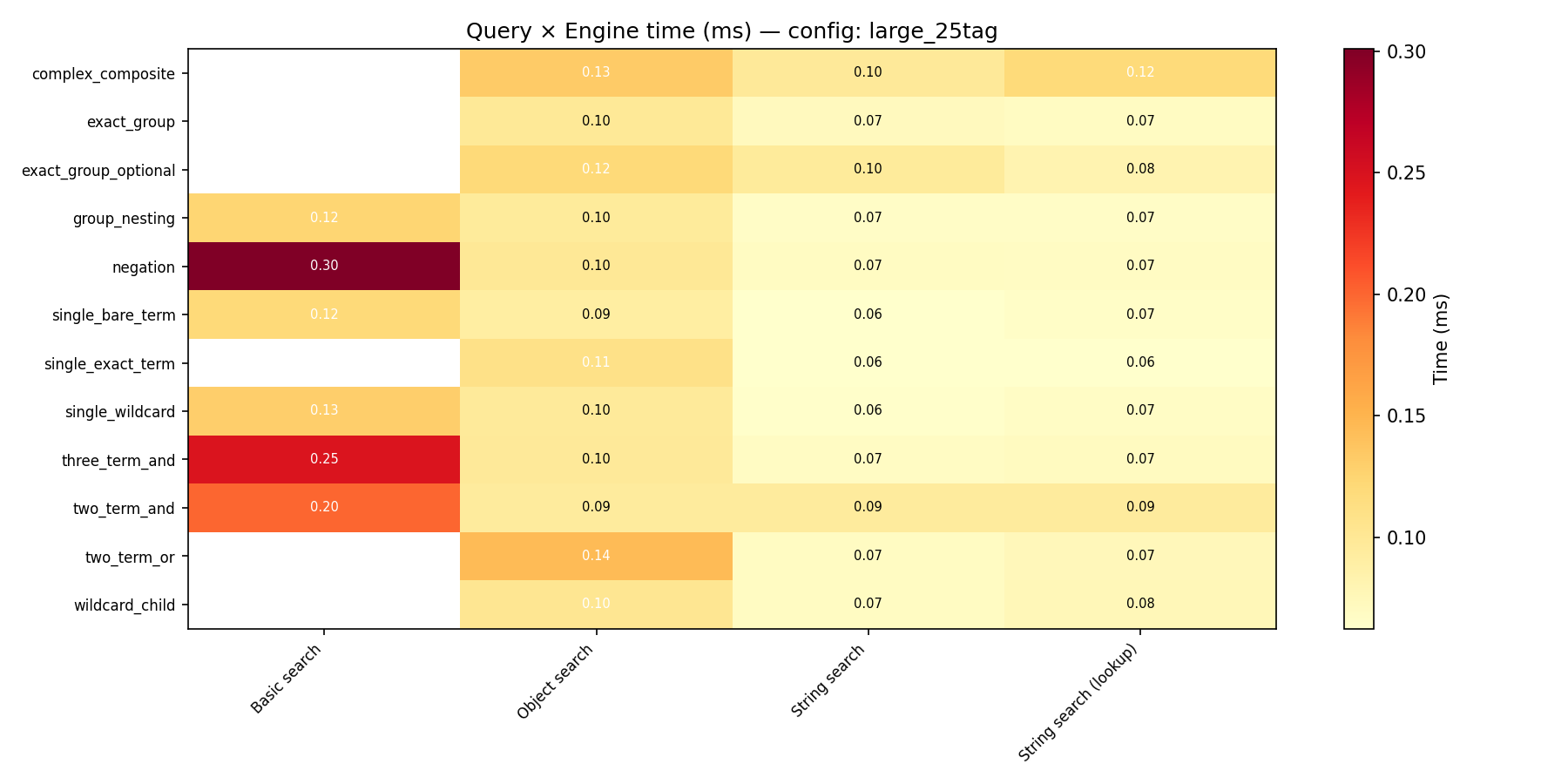
Per-string median search time (ms) across string sizes. Tag counts: tiny = 1, small = 5, medium = 10, large = 25, xlarge = 50, xxlarge = 100. Larger strings also contain nested groups (e.g. large = 5 groups at depth 2). The table below is filtered to the bare_term query (Event / @Event) to isolate parse and tree-walk cost from query complexity; see the query heatmap image below for all 12 queries.
(Example 10-tag string: Human-agent, Move, Computed-feature, Age, Aroused, 3D-shape, Little-toe, To-right-of, Brain-region, DarkSeaGreen)
String size |
Object search (ms) |
String search (ms) |
Basic search (ms) |
|---|---|---|---|
tiny (1 tag) |
0.012 |
0.007 |
0.131 |
small (5 tags) |
0.020 |
0.014 |
0.197 |
medium (10 tags) |
0.041 |
0.021 |
0.123 |
large (25 tags) |
0.132 |
0.102 |
0.157 |
xlarge (50 tags) |
0.176 |
0.113 |
0.131 |
xxlarge (100 tags) |
0.329 |
0.248 |
0.154 |
Basic search regex overhead dominates on small strings; object search and string search dominate on large strings. The crossover occurs around 25–50 tags.
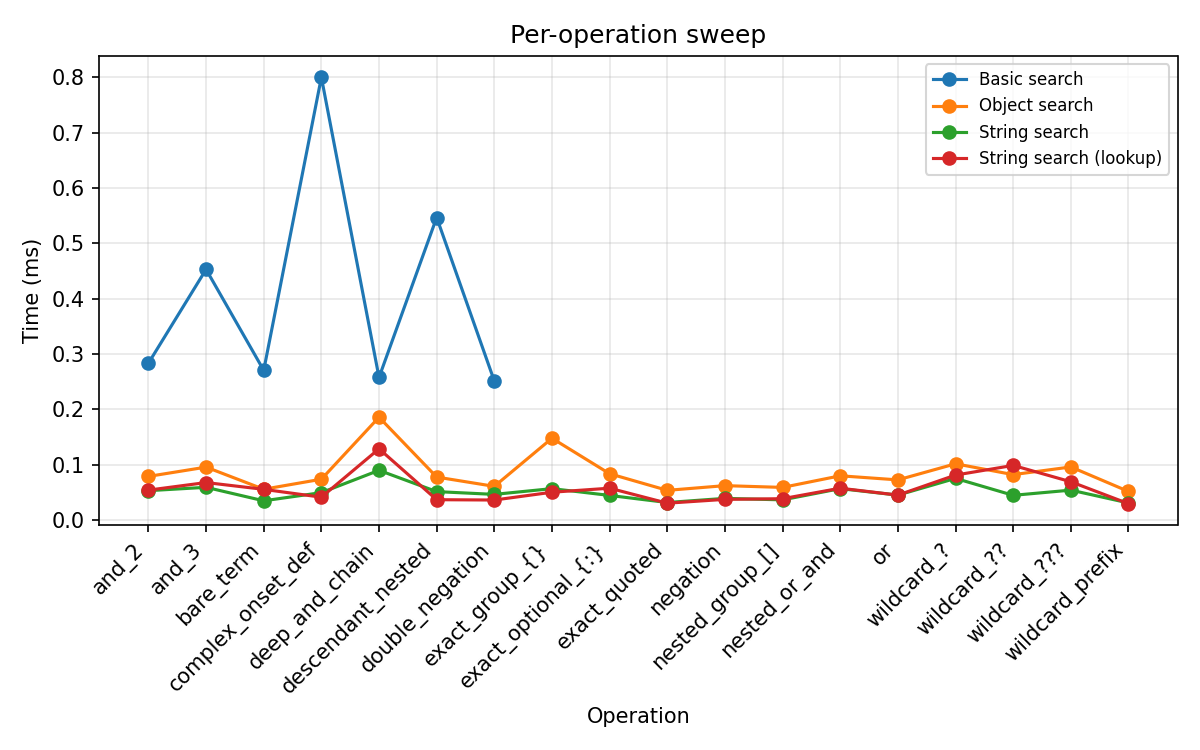
Operation coverage and cost¶
Per-operation timing on a fixed structured string using all 18 operations from the query suite above. Basic search is slower than the tree-based engines on a single string — its speed advantage only appears for large batches, where vectorized pandas regex amortises the per-call overhead across many rows (see Row-by-row search scaling). Basic search returns no results (not an error) for unsupported constructs, so queries using those operations will silently produce incorrect results.
(Example string: Sensory-event, Action, Agent, (Event, (Onset, (Def/MyDef))), (Offset, Item, (Def-expand/MyDef, (Red, Blue))), (Visual-presentation, Square, Green))
Operation |
Object search (ms) |
String search (ms) |
Basic search |
|---|---|---|---|
|
0.061 |
0.037 |
0.278 ms |
|
0.063 |
0.041 |
0.321 ms |
|
0.067 |
0.045 |
0.355 ms |
|
0.083 |
0.043 |
0.160 ms |
|
0.046 |
0.037 |
0.204 ms |
|
0.057 |
0.039 |
0.634 ms |
|
0.117 |
0.059 |
0.515 ms |
|
0.058 |
0.037 |
— unsupported |
|
0.052 |
0.030 |
— unsupported |
|
0.071 |
0.043 |
— unsupported |
|
0.062 |
0.030 |
— unsupported |
|
0.086 |
0.047 |
— unsupported |
|
0.068 |
0.041 |
— unsupported |
|
0.074 |
0.041 |
— unsupported |
|
0.138 |
0.086 |
— unsupported |
|
0.057 |
0.035 |
— unsupported |
|
0.113 |
0.068 |
— unsupported |
|
0.080 |
0.057 |
— unsupported |
String search supports all 18 operation types.
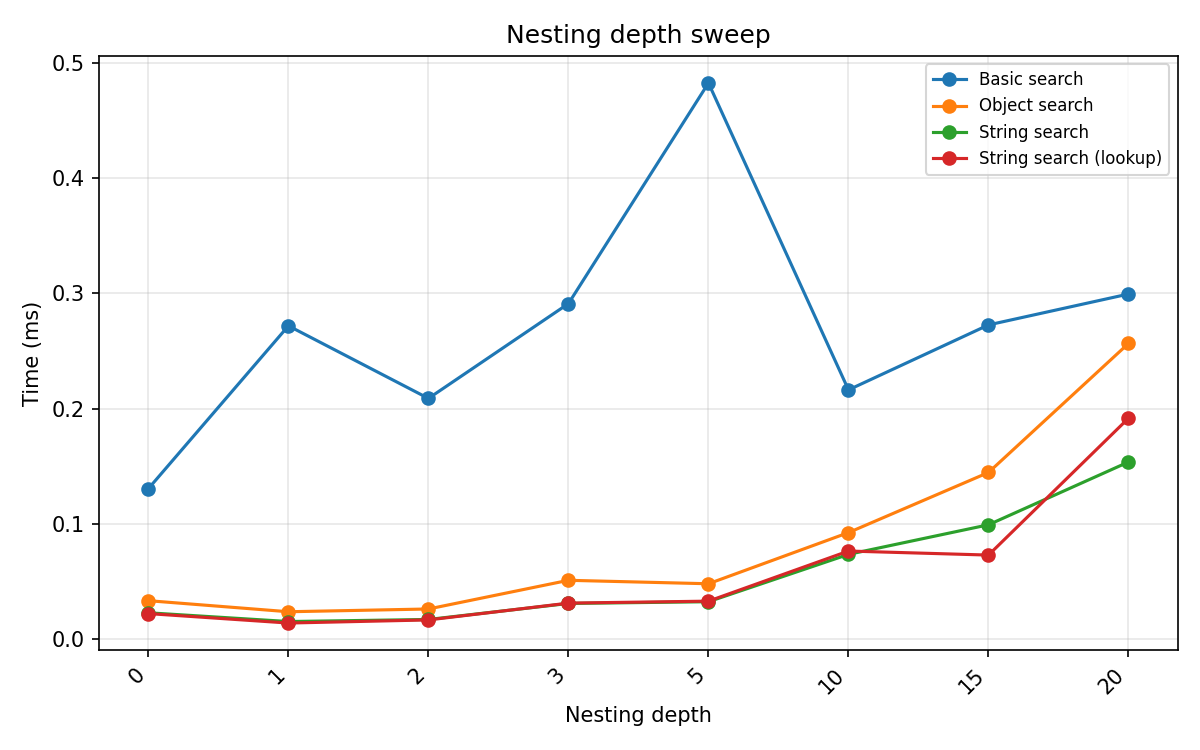
Nesting depth¶
Parenthesisation depth from 0 (flat) to 20. Deeper nesting increases the tree walk for Object search and String search. Basic search shows no consistent depth trend because its cost depends on delimiter count, not recursion depth.
(Example string at depth 3, query Event: Event, Action, (Cough, River, ((Catamenial, Background-subtask, ((Eyelid, Comatose, (Flex, Move-body)))))))
Depth |
Object search (ms) |
String search (ms) |
Basic search (ms) |
|---|---|---|---|
0 |
0.026 |
0.017 |
0.125 |
1 |
0.022 |
0.013 |
0.256 |
2 |
0.028 |
0.019 |
0.218 |
3 |
0.034 |
0.023 |
0.215 |
5 |
0.110 |
0.076 |
0.531 |
10 |
0.094 |
0.060 |
0.385 |
15 |
0.116 |
0.082 |
0.226 |
20 |
0.409 |
0.140 |
0.200 |
At depth 20, object search is ~8× slower than at depth 0; string search is ~8× slower.
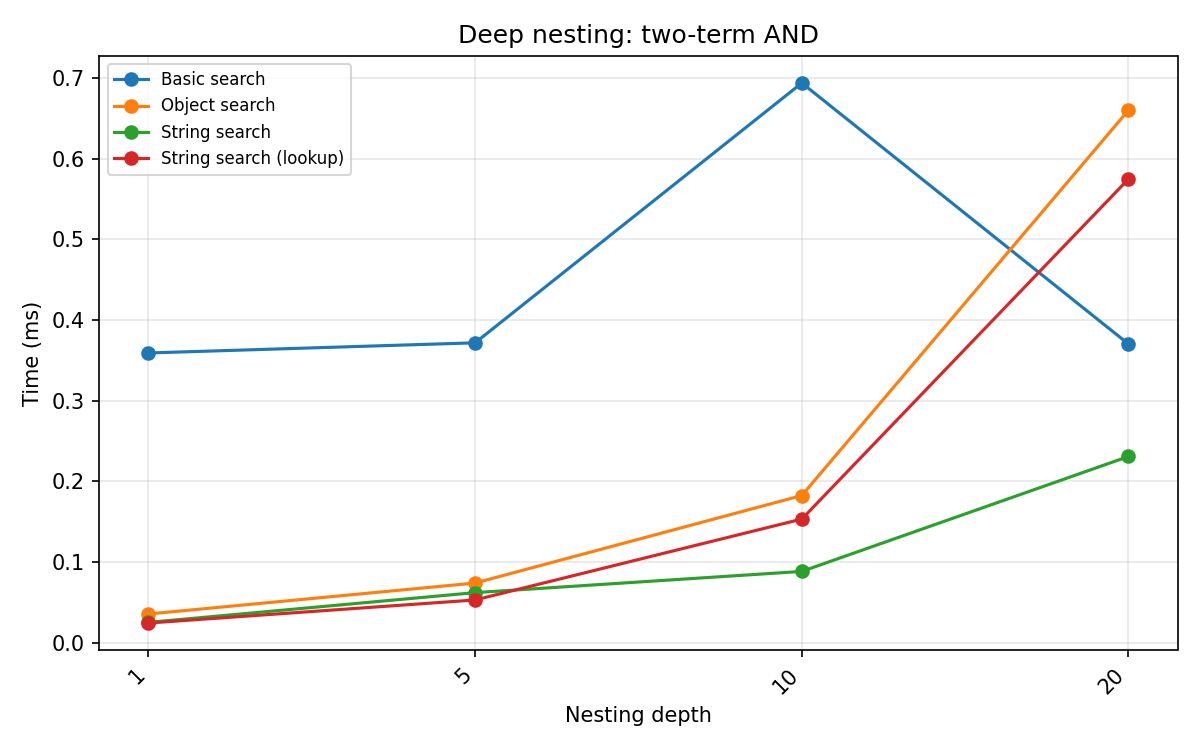
Deep nesting by query type¶
The nesting cost depends on query type. For group-structural queries (group_match, two_term_and) the engines must evaluate all candidate groups at each level, and object search shows a pronounced cost spike at depth 10 while string search stays flatter. All values in ms at depths 1–20.
(Example string at depth 5: Event, Action, (Drop, Jealous, ((Drowsy, Angle, ((Sound-envelope, Pause, ((Headphones, Khaki, ((Adjacent-to, Age, (Ride, Measurement-device)))))))))))
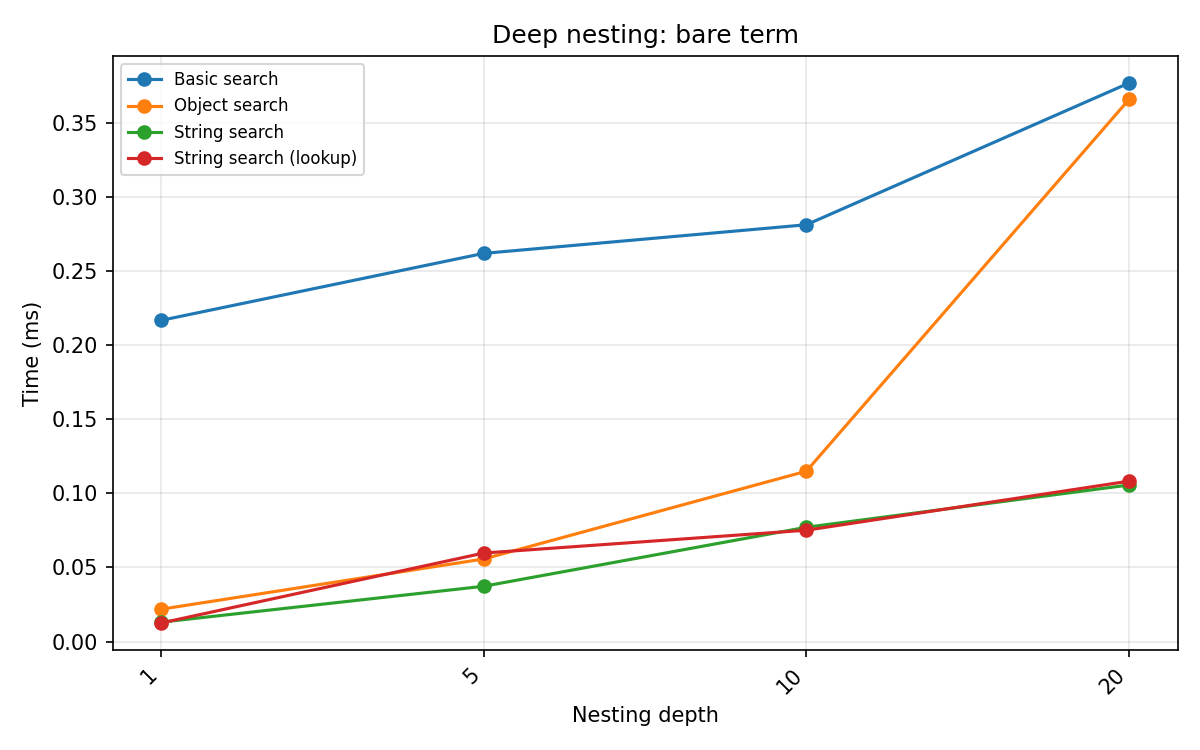
Bare term:
Depth |
Object search |
String search |
Basic search |
|---|---|---|---|
1 |
0.030 |
0.019 |
0.204 |
5 |
0.045 |
0.031 |
0.198 |
10 |
0.087 |
0.059 |
0.209 |
20 |
0.141 |
0.154 |
0.212 |
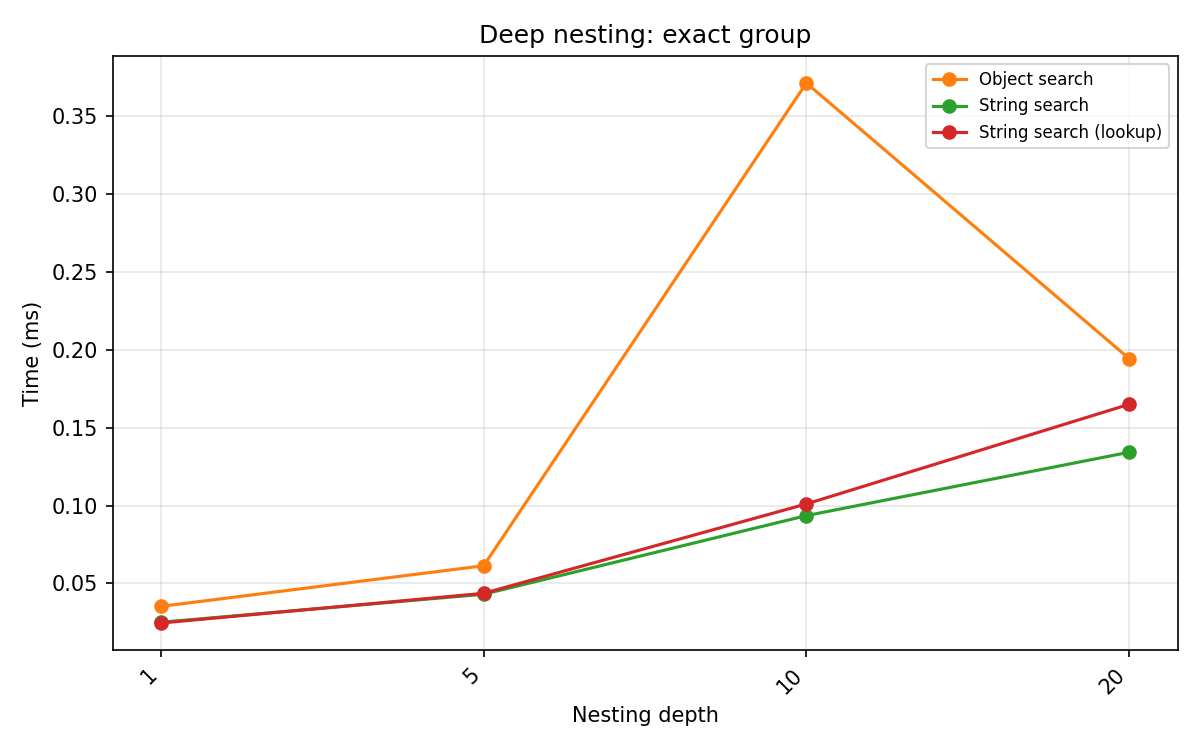
Exact group {}:
Depth |
Object search |
String search |
|---|---|---|
1 |
0.025 |
0.018 |
5 |
0.053 |
0.036 |
10 |
0.105 |
0.072 |
20 |
0.209 |
0.146 |
Group match []:
Depth |
Object search |
String search |
Basic search |
|---|---|---|---|
1 |
0.032 |
0.020 |
0.520 |
5 |
0.054 |
0.038 |
0.551 |
10 |
0.181 |
0.063 |
0.536 |
20 |
0.324 |
0.118 |
0.658 |
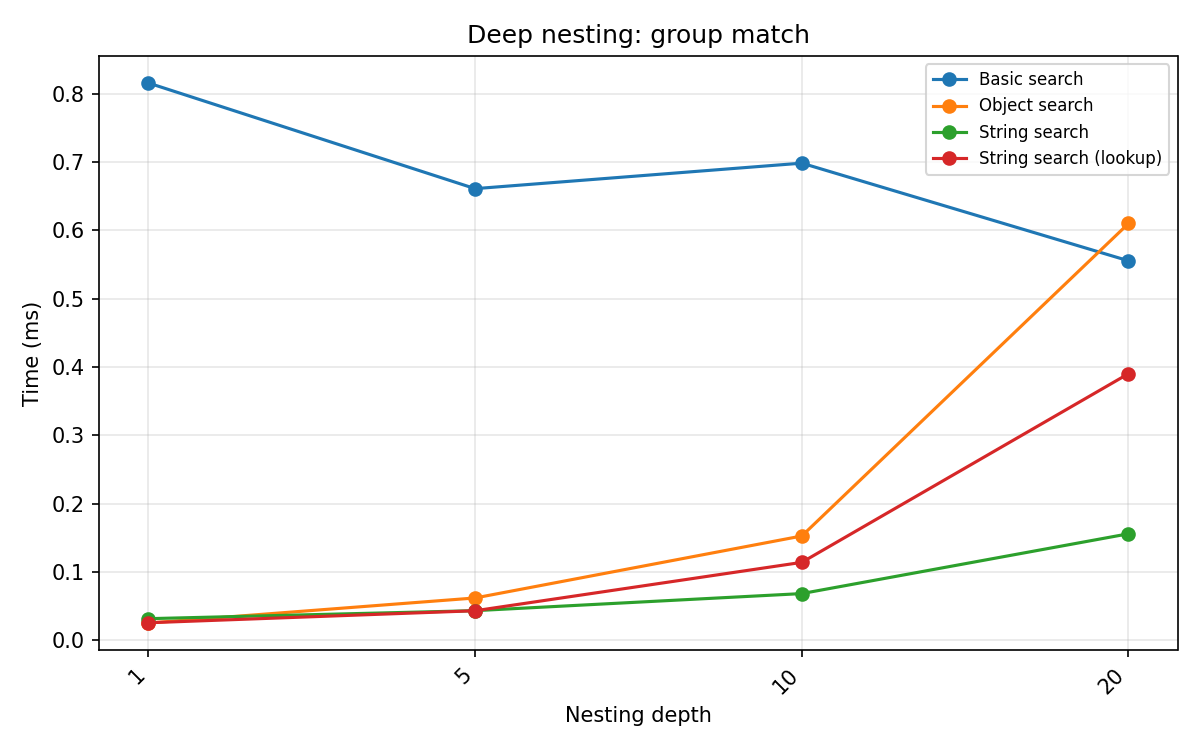
Object search at depth 10 is 5.7× its depth-1 cost; string search is only 3.2×.
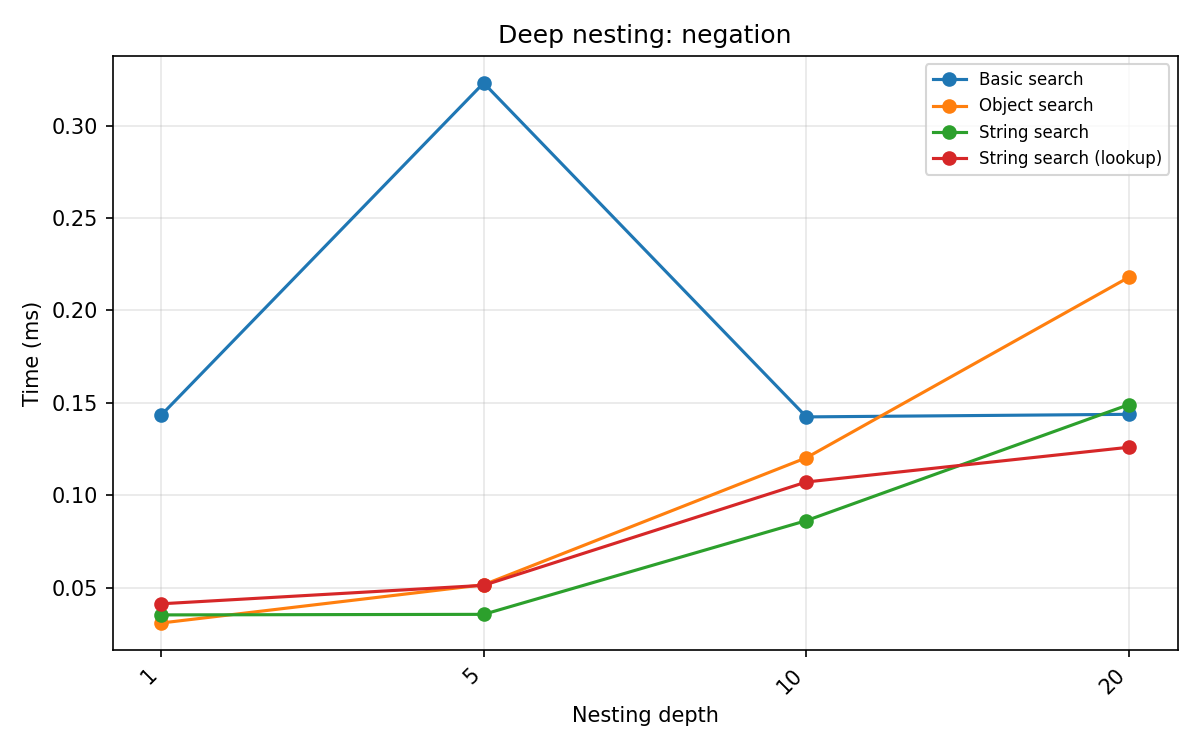
Negation:
Depth |
Object search |
String search |
Basic search |
|---|---|---|---|
1 |
0.021 |
0.014 |
0.128 |
5 |
0.055 |
0.037 |
0.163 |
10 |
0.101 |
0.072 |
0.121 |
20 |
0.177 |
0.129 |
0.112 |
Two-term AND:
Depth |
Object search |
String search |
Basic search |
|---|---|---|---|
1 |
0.043 |
0.024 |
0.422 |
5 |
0.065 |
0.052 |
0.395 |
10 |
0.205 |
0.070 |
0.274 |
20 |
0.320 |
0.109 |
0.355 |
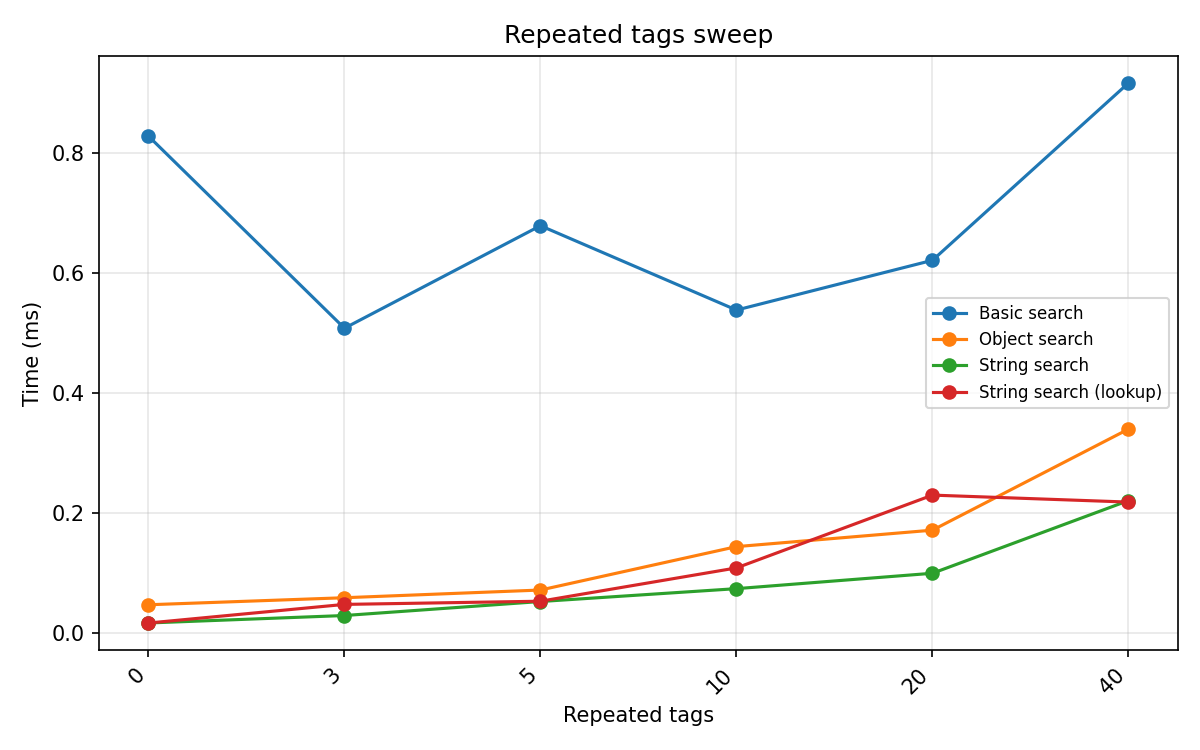
Repeated tags¶
Repeating a target tag N times in the string. Basic search’s verify_search_delimiters uses itertools.product over delimiter positions; repeated instances multiply the internal search space. Tree-based engines are linear in the number of candidates and are not affected.
(Example with 3 repeats of Event, query (Event, Action): Event, Green-color, Event, Action, Event, To-right-of, (Locked-in, Event))
Occurrences |
Object search (ms) |
String search (ms) |
Basic search (ms) |
|---|---|---|---|
0 |
0.034 |
0.022 |
0.544 |
5 |
0.151 |
0.084 |
0.791 |
10 |
0.093 |
0.073 |
0.940 |
20 |
0.182 |
0.138 |
0.668 |
40 |
0.200 |
0.195 |
0.654 |
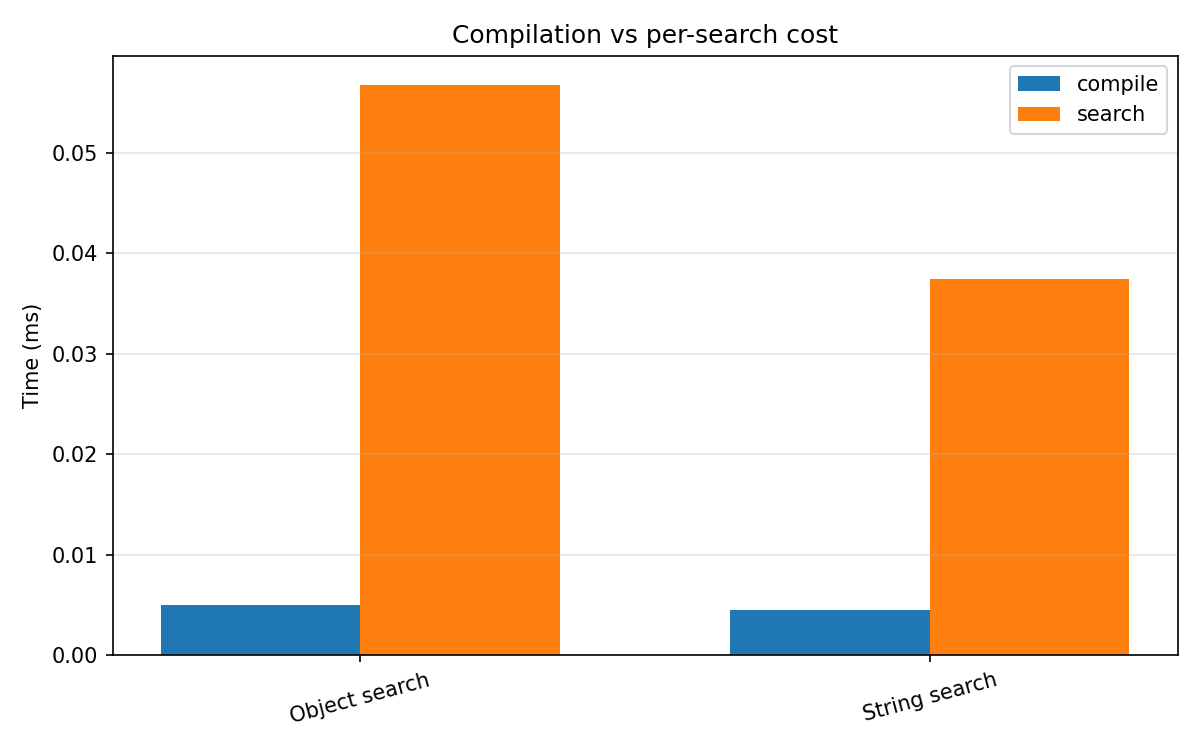
Compile vs. search¶
Query compilation is a one-time cost; subsequent searches against different strings reuse the compiled expression. Reusing a compiled handler across many strings amortises compilation cost to near zero.
(Example string, query Event: Statistical-uncertainty, Categorical-value, Tablet-computer, Agent-cognitive-state, Data-median, Little-toe, Eye, Sound-envelope-attack, Nose, (Description, Discrete), (Electrode-movement-artifact, Burp), (Snow, Between))
Phase |
Object search (ms) |
String search (ms) |
|---|---|---|
Compile |
0.004 |
0.005 |
Search |
0.053 |
0.036 |
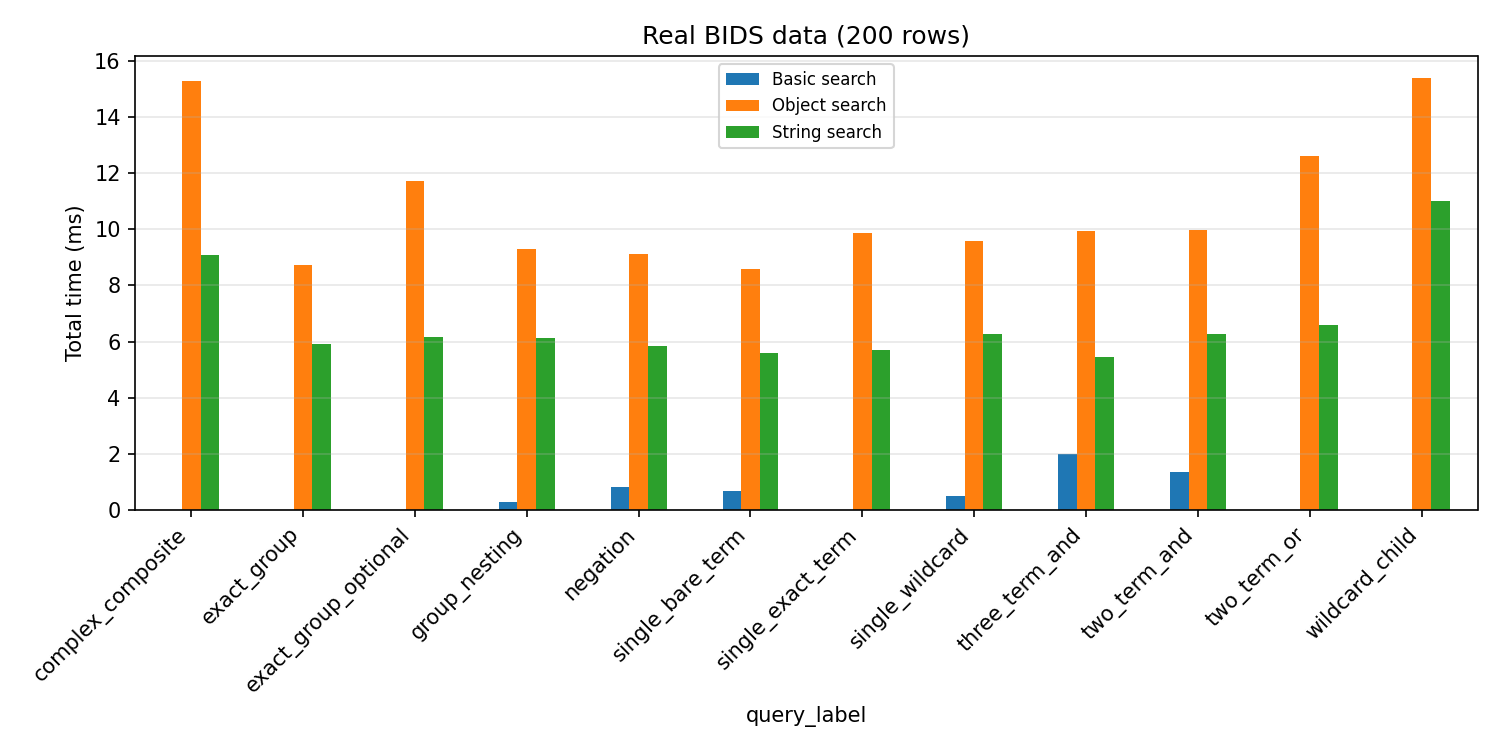
Real BIDS data¶
Search over 200 rows of the eeg_ds003645s_hed BIDS test dataset.
(Example row: Sensory-event, Experimental-stimulus, (Def/Face-image, Onset), (Def/Blink-inhibition-task, Onset), (Def/Fixation-task, Onset), Def/Unfamiliar-face-cond, Def/First-show-cond, (Image, Pathname/u032.bmp))
Query |
Object search (ms) |
Basic search (ms) |
String search (ms) |
|---|---|---|---|
|
9.0 |
2.5 |
6.5 |
|
8.2 |
0.6 |
4.9 |
|
8.0 |
0.9 |
6.8 |
|
8.8 |
1.2 |
4.9 |
|
8.5 |
1.9 |
5.1 |
|
7.9 |
0.3 |
7.8 |
|
7.9 |
— |
6.8 |
|
9.3 |
— |
6.6 |
|
11.7 |
— |
5.8 |
|
8.1 |
— |
5.5 |
|
12.6 |
— |
8.9 |
|
14.2 |
— |
9.5 |
Tag count¶
Number of tags in the HED string (1 to 100), query Event. Basic search time is dominated by regex compilation overhead and stays roughly constant; tree-based engines scale linearly with the number of nodes to traverse.
(Example 10-tag string: Human-agent, Move, Computed-feature, Age, Aroused, 3D-shape, Little-toe, To-right-of, Brain-region, DarkSeaGreen)
Tags |
Object search (ms) |
String search (ms) |
Basic search (ms) |
|---|---|---|---|
1 |
0.014 |
0.004 |
0.294 |
5 |
0.019 |
0.013 |
0.163 |
10 |
0.031 |
0.018 |
0.150 |
25 |
0.061 |
0.080 |
0.124 |
50 |
0.149 |
0.160 |
0.184 |
100 |
0.287 |
0.167 |
0.271 |
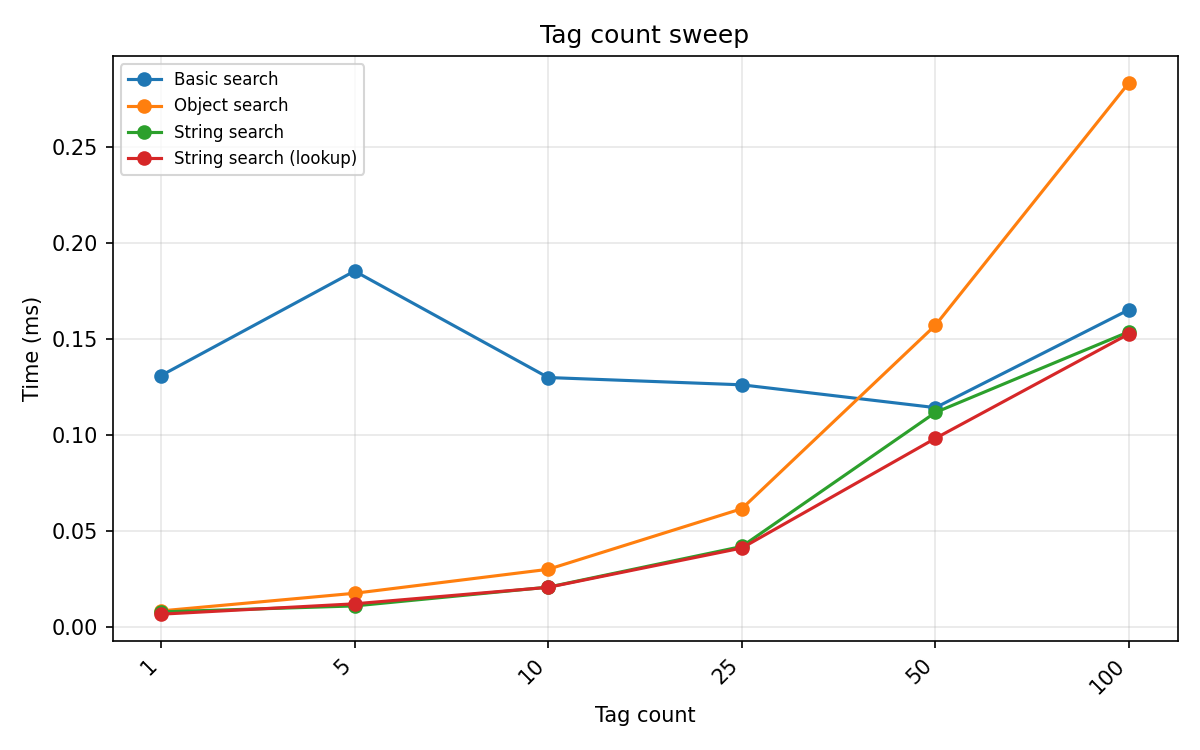
The tree-based crossover with basic search occurs around 25–50 tags, where traversal cost meets the regex setup cost.
String form¶
Short-form vs long-form HED strings, query Event. Long-form strings use fully expanded paths (e.g. Event/Sensory-event), increasing string length and parse cost. Basic search is largely unaffected because it matches on short tag names via word-boundary patterns.
(Example short-form string: Yawn, Frustrated, Famous, Plan, Catamenial, Instep, Sound-envelope-attack, Categorical-value, Azure, (Species-identifier, Auditory-device), (Collection, Muddy-terrain), (Alarm-sound, Data-marker))
Form |
Object search (ms) |
String search (ms) |
Basic search (ms) |
|---|---|---|---|
short |
0.044 |
0.029 |
0.124 |
long |
0.074 |
0.063 |
0.121 |
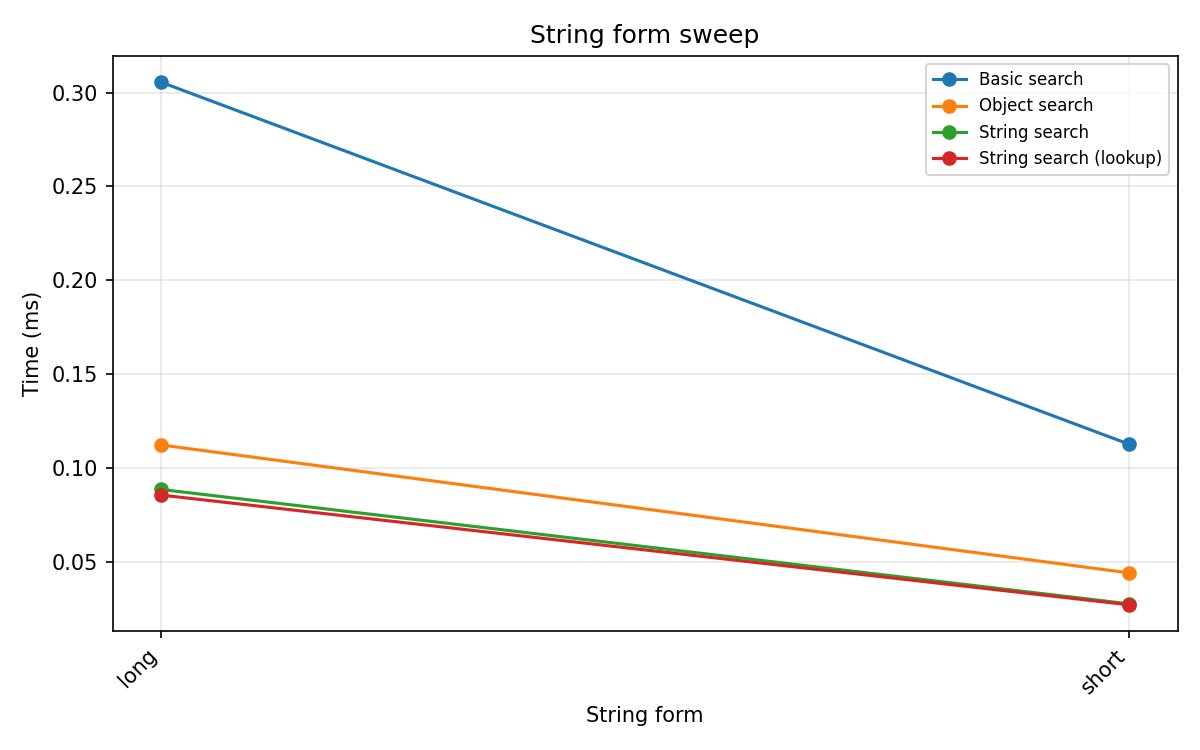
Object search is 1.7× slower on long-form strings; string search is 2.2× slower.
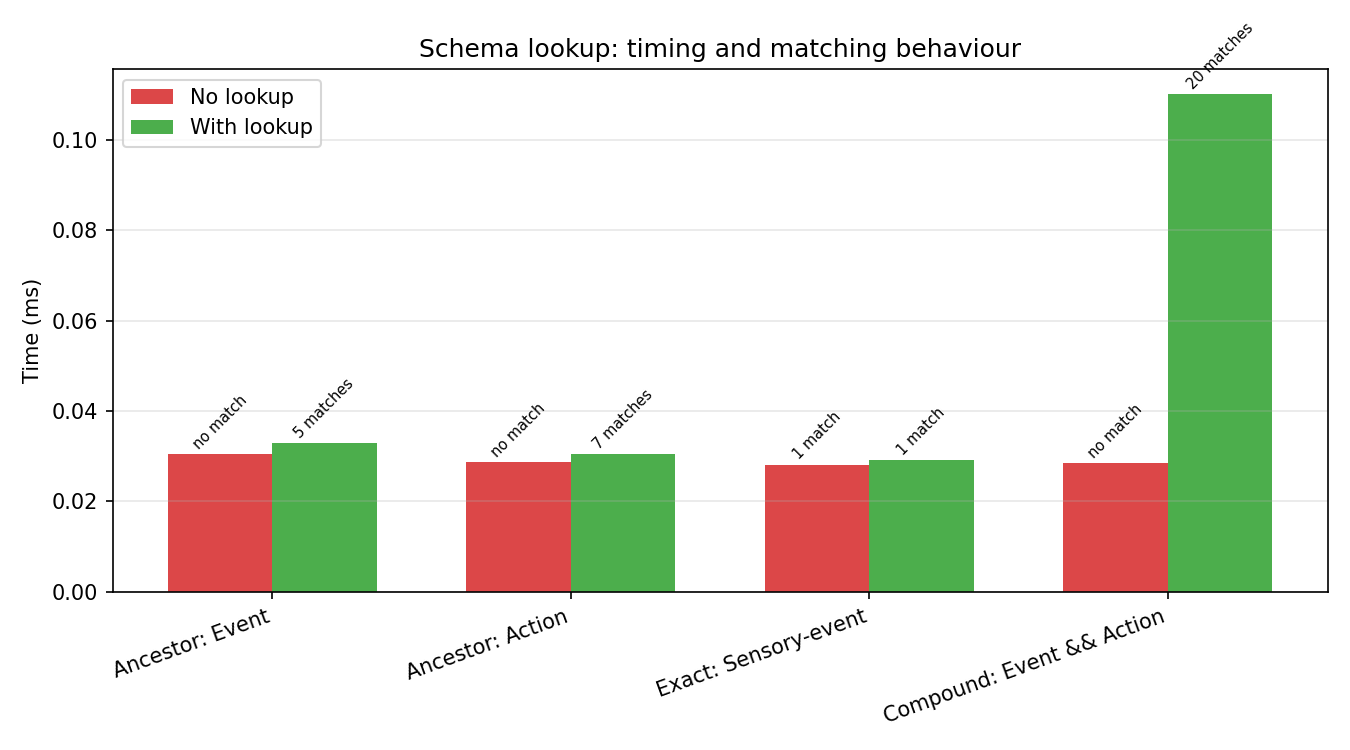
Schema lookup overhead¶
The schema_lookup dictionary (produced by generate_schema_lookup(schema)) determines whether string search resolves parent-class queries. Without it, a bare term matches only the exact tag name literally present in the string. With it, every tag carries its full ancestor path from the schema, so a query like Event correctly matches any descendant such as Sensory-event or Agent-action.
The table below uses a fixed short-form string that contains known Event and Action descendants (Sensory-event, Agent-action, Data-feature, Communicate, Clap-hands, …) to make the correctness difference explicit.
Query |
No lookup: time (ms) |
No lookup: matches |
With lookup: time (ms) |
With lookup: matches |
|---|---|---|---|---|
Ancestor: Event |
0.031 |
0 |
0.031 |
5 |
Ancestor: Action |
0.029 |
0 |
0.033 |
7 |
Exact: Sensory-event |
0.028 |
1 |
0.052 |
1 |
Compound: Event && Action |
0.022 |
0 |
0.087 |
20 |
Key observations:
Ancestor queries without lookup silently return zero matches. This is a correctness issue, not a performance trade-off — if you search for
Eventon short-form strings without a lookup table, you will miss every row containing only descendants likeSensory-event.Exact queries work without lookup and are slightly faster because no ancestor-tuple construction occurs.
With lookup, compound ancestor queries are noticeably slower (0.087 ms vs 0.022 ms here) because the engine produces many more match results when hierarchical expansion is active.
Long-form strings (
Event/Sensory-event) do not need a lookup table — the slash path already encodes the ancestor chain. Usestring_form="long"or convert first withconvert_to_form()if you want ancestor matching without the lookup overhead.
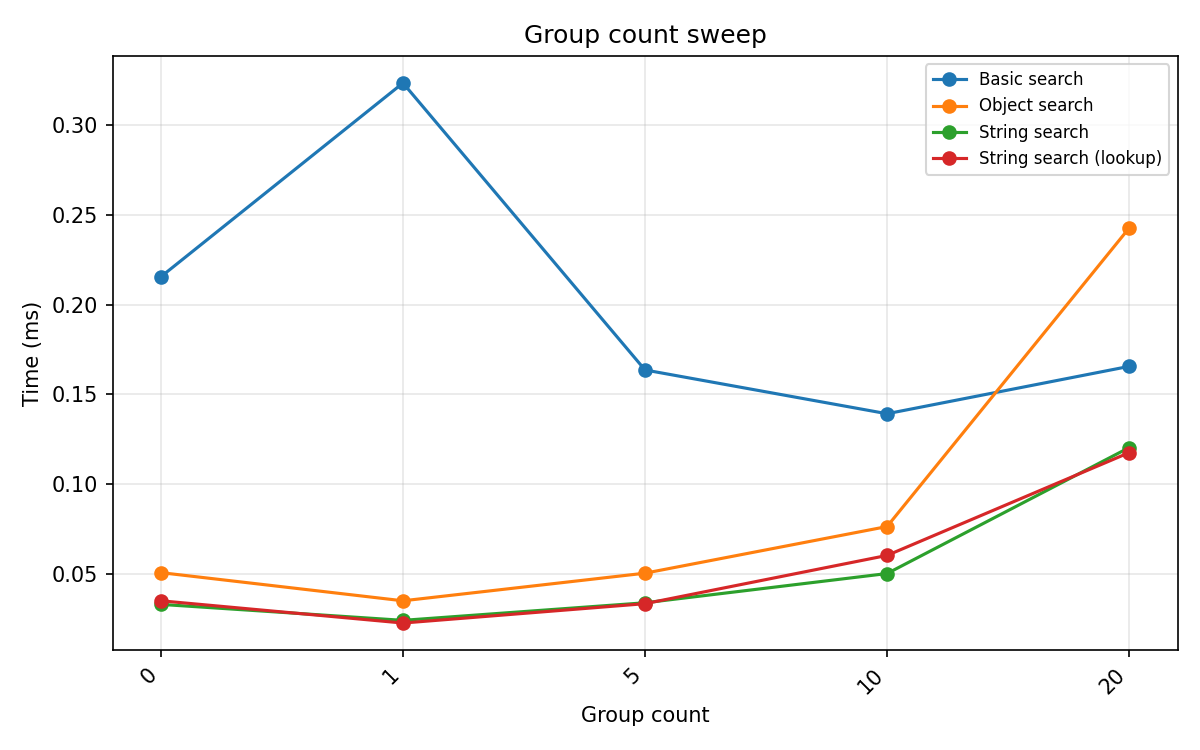
Group count and query complexity¶
More top-level parenthesised groups increase the number of children the tree must inspect. Query complexity (more AND/OR clauses) adds expression-tree nodes to evaluate per candidate.
Group count (0–20 single-level groups, query Event. Example at 5 groups: Statistical-uncertainty, Categorical-value, Tablet-computer, (Agent-cognitive-state, Data-median), (Little-toe, Eye), (Sound-envelope-attack, Nose), (Description, Discrete), (Electrode-movement-artifact, Burp)):
Groups |
Object search (ms) |
String search (ms) |
Basic search (ms) |
|---|---|---|---|
0 |
0.032 |
0.022 |
0.139 |
1 |
0.028 |
0.019 |
0.129 |
5 |
0.045 |
0.030 |
0.114 |
10 |
0.080 |
0.053 |
0.135 |
20 |
0.140 |
0.085 |
0.136 |
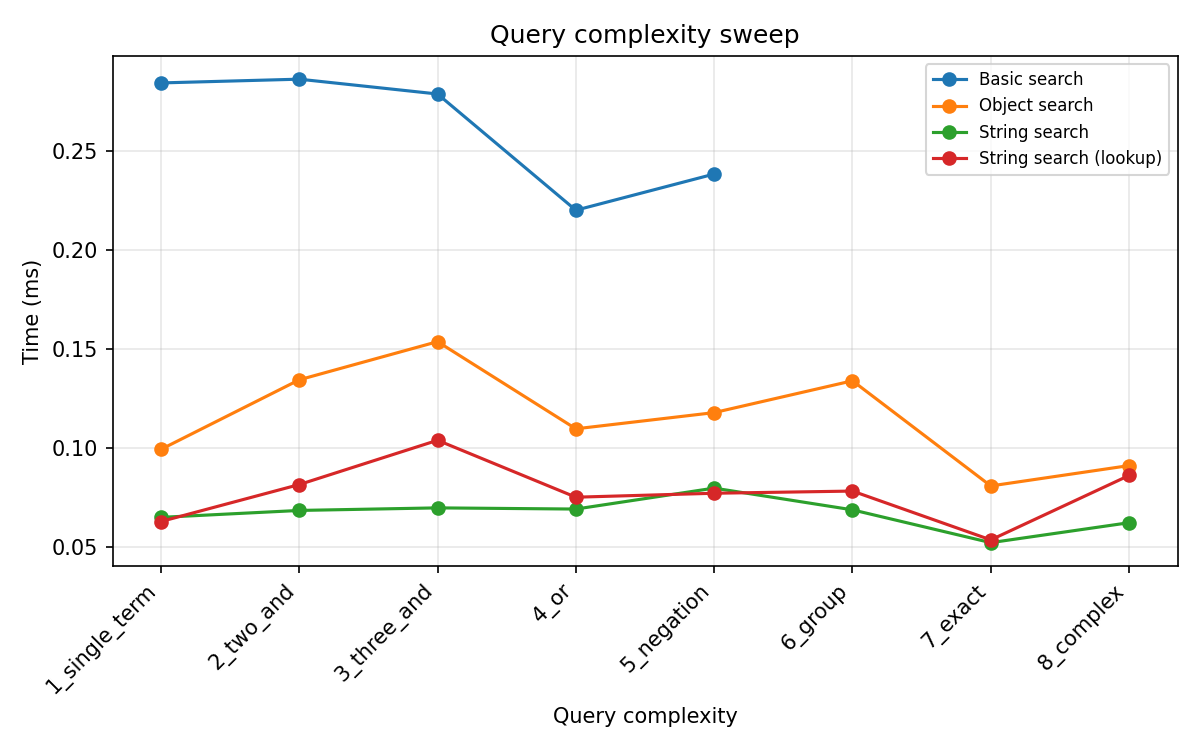
Query complexity (1-clause bare term → 8-clause composite. Example string: Human-agent, Move, Computed-feature, Age, Aroused, 3D-shape, Little-toe, To-right-of, Brain-region, DarkSeaGreen, (FireBrick, (Flex, Move-body)), (Categorical-value, (Eyelid, Comatose)), (Robotic-agent, (Catamenial, Background-subtask)), (Keyboard, (Cough, River)), (ForestGreen, (Green-color, Locked-in))):
Complexity |
Object search (ms) |
String search (ms) |
Basic search |
|---|---|---|---|
1 — single term |
0.134 |
0.100 |
0.247 ms |
2 — two AND |
0.152 |
0.093 |
0.405 ms |
3 — three AND |
0.158 |
0.103 |
0.460 ms |
4 — OR |
0.134 |
0.071 |
— |
5 — negation |
0.088 |
0.056 |
0.286 ms |
6 — group |
0.138 |
0.094 |
0.361 ms |
7 — exact group |
0.120 |
0.078 |
— |
8 — complex composite |
0.106 |
0.078 |
— |
Choosing an implementation¶
Use basic search when you need the fastest possible batch filter, your queries can be expressed with simple terms, AND, negation, or descendant wildcards (*), and schema-aware ancestor matching is not required. Ideal for quick event file filtering when query simplicity is acceptable.
Use string search (via string_search()) when you need the full query language (OR, exact groups, logical groups, ?/??/??? wildcards) and are working with raw strings from tabular files or sidecars. This is the best general-purpose choice — it is ~39% faster than an object search loop per string and close to basic search on large strings.
Use object search when you already have parsed HedString objects (for example from a validation pipeline), or when you need results as structured HedString/HedTag objects rather than boolean matches. The additional overhead relative to string search comes from HedString construction, not from search expression evaluation, so reusing pre-parsed objects avoids the cost entirely.
Benchmark methodology¶
Timing:
timeit— 20 iterations (single-string), 5 iterations (list search), 10 iterations (sweeps). Median reported.Schema: HED 8.4.0, loaded once and reused.
Synthetic data: Strings built from real schema tags with controlled tag count, nesting depth, group count, and tag repetition.
schema_lookup: Generated viagenerate_schema_lookup(schema)— a dict mapping each short tag to its ancestor tuple, enabling ancestor-based matching in string search without a full schema load per string.Hardware note: Absolute timings depend on hardware; relative ratios between engines are the meaningful comparison.